nimare.decode.encode.gclda_encode¶
-
gclda_encode(model, text, out_file=None, topic_priors=None, prior_weight=1.0)[source]¶ Perform text-to-image encoding according to the method described in [1].
Parameters: - model (
nimare.annotate.topic.GCLDAModel) – Model object needed for decoding. - text (
strorlist) – Text to encode into an image. - out_file (
str, optional) – If not None, writes the encoded image to a file. - topic_priors (
numpy.ndarrayoffloat, optional) – A 1d array of size (n_topics) with values for topic weighting. If None, no weighting is done. Default is None. - prior_weight (
float, optional) – The weight by which the prior will affect the encoding. Default is 1.
Returns: - img (
nibabel.nifti1.Nifti1Image) – The encoded image. - topic_weights (
numpy.ndarrayoffloat) – The weights of the topics used in encoding.
Notes
Notation Meaning 
Voxel 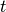
Topic 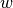
Word type 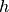
Input text 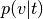
Probability of voxel given topic ( p_voxel_g_topic_)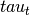
Topic weight vector ( topic_weights)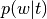
Probability of word type given topic ( p_word_g_topic)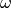
1d array from input image ( input_values)Compute
(p_voxel_g_topic).- From
gclda.model.Model.get_spatial_probs()
- From
Compute
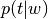 (
(p_topic_g_word).Vectorize input text according to model vocabulary.
Reduce
to only include word types in input text.Compute
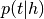 (
(p_topic_g_text) by multiplying by word counts for input text.Sum topic weights (
) across
words.Compute voxel weights.
The resulting array (
voxel_weights) reflects arbitrarily scaled voxel weights for the input text.Unmask and reshape
voxel_weightsinto brain image.
References
[1] Rubin, Timothy N., et al. “Decoding brain activity using a large-scale probabilistic functional-anatomical atlas of human cognition.” PLoS computational biology 13.10 (2017): e1005649. https://doi.org/10.1371/journal.pcbi.1005649 - model (