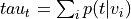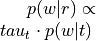nimare.decode.discrete.gclda_decode_roi
- gclda_decode_roi(model, roi, topic_priors=None, prior_weight=1.0)[source]
Perform image-to-text decoding for discrete inputs using method from Rubin et al. (2017).
The method used in this function was originally described in Rubin et al.[1].
- Parameters:
model (
GCLDAModel) – Model object needed for decoding.roi (
nibabel.nifti1.Nifti1Imageorstr) – Binary image to decode into text. If string, path to a file with the binary image.topic_priors (
numpy.ndarrayoffloat, optional) – A 1d array of size (n_topics) with values for topic weighting. If None, no weighting is done. Default is None.prior_weight (
float, optional) – The weight by which the prior will affect the decoding. Default is 1.
- Returns:
decoded_df (
pandas.DataFrame) – A DataFrame with the word-tokens and their associated weights.topic_weights (
numpy.ndarrayoffloat) – The weights of the topics used in decoding.
Notes
Notation
Meaning

Voxel
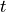
Topic
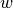
Word type

Region of interest (ROI)
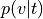
Probability of topic given voxel (
p_topic_g_voxel)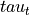
Topic weight vector (
topic_weights)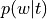
Probability of word type given topic (
p_word_g_topic)Compute
.From
gclda.model.Model.get_spatial_probs()
Compute topic weight vector (
) by adding across voxels within ROI.Multiply
by .The resulting vector (
word_weights) reflects arbitrarily scaled term weights for the ROI.
See also
References