nimare.nimads.Studyset
- class Studyset(source, target=<object object>, mask=None, annotations=None, basepath=None, harmonize_coordinates=True)[source]
Bases:
objectA collection of studies for meta-analysis.
Added in version 0.0.14.
This is the primary target for Estimators and Transformers in NiMARE.
- Variables:
id (str) – A unique identifier for the Studyset.
name (str) – A human-readable name for the Studyset.
annotations (
listofnimare.nimads.Annotationobjects) – The Annotation objects associated with the Studyset.studies (
listofnimare.nimads.Studyobjects) – The Study objects comprising the Studyset.
Methods
Combine analyses in Studyset.
copy()Create a copy of the Studyset.
exclude_study_ids(study_ids)Return a Studyset excluding analyses belonging to the given study IDs.
filter_annotations(labels[, threshold, match])Return a Studyset filtered by annotation labels.
filter_ids(ids)Return a Studyset filtered to the requested analysis IDs.
filter_metadata(field, op, value)Return a Studyset filtered by one metadata field.
filter_study_ids(study_ids)Return a Studyset keeping only analyses belonging to the given study IDs.
from_dataset(dataset, *[, materialize])Create a Studyset from a NiMARE Dataset.
from_nimads(filename)Create a Studyset from a NIMADS JSON file.
from_sleuth(sleuth_file)Create a Studyset from a Sleuth text file.
from_table_cache(table_cache, *[, ...])Create a lightweight Studyset backed by precomputed Dataset-style tables.
get(dict_[, drop_invalid])Retrieve files and/or metadata from the current Studyset.
get_analyses_by_annotations(key[, value])Extract a list of Analyses with a given label/annotation.
get_analyses_by_coordinate(xyz[, r, n])Extract a list of Analyses with at least one Point near the requested coordinates.
get_analyses_by_label([labels, label_threshold])Extract analysis IDs whose annotation values exceed the threshold.
get_analyses_by_mask(img)Extract a list of Analyses with at least one Point in the specified mask.
get_analyses_by_metadata(key[, value])Extract a list of Analyses with a metadata field/value.
get_annotations(analyses)Collect Annotations associated with specified Analyses.
get_images([analyses, imtype, ids])Get image paths or collect nested Image objects by short analysis IDs.
get_labels([ids])Extract labels present in the Studyset's analysis-level annotations.
get_metadata([analyses, field, ids])Get metadata values or collect nested metadata by short analysis IDs.
get_points(analyses)Collect Points associated with specified Analyses.
get_studies_by_coordinate(xyz[, r])Extract full analysis IDs with at least one focus near the requested coordinates.
get_studies_by_label([labels, label_threshold])Extract full analysis IDs whose annotation values exceed the threshold.
get_studies_by_mask(mask)Extract full analysis IDs with at least one focus inside
mask.get_texts([analyses, text_type, ids])Get texts for selected analyses or collect nested texts by short analysis IDs.
load(filename)Load a Studyset from a pickled file.
Materialize the nested Study/Analysis graph if this Studyset is lazy.
merge(right)Merge a separate Studyset into the current one.
save(filename)Write the Studyset to a pickled file.
set_annotations_df(annotations_df[, overwrite])Update analysis-level annotations from a flattened DataFrame.
slice([ids, analyses, filter_level])Create a new Studyset keeping only the requested IDs.
Convert the Studyset to a NiMARE Dataset.
to_dict()Return a dictionary representation of the Studyset.
to_nimads(filename)Write the Studyset to a NIMADS JSON file.
touch()Invalidate Studyset-derived caches after in-place mutation.
update_path(new_path)Prepend a base path for relative image paths in the Studyset.
Properties
Return existing Annotations.
Flattened analysis-level annotations table.
Base path used for image resolution in Dataset-like Studyset views.
Dataset-like coordinates table.
1D array of full analysis identifiers.
Dataset-like images table.
Whether the Studyset has an explicit execution configuration.
Whether the nested Study/Analysis graph has been materialized.
Masker used for Dataset-like Studyset views.
Dataset-like metadata table.
Execution-space label used for Dataset-like Studyset views.
Return the nested Study graph, materializing it on demand if needed.
1D array of unique study identifiers.
Dataset-like texts table.
- property annotations
Return existing Annotations.
- property annotations_df
Flattened analysis-level annotations table.
- Type:
- property basepath
Base path used for image resolution in Dataset-like Studyset views.
- property coordinates
Dataset-like coordinates table.
- Type:
- exclude_study_ids(study_ids)[source]
Return a Studyset excluding analyses belonging to the given study IDs.
- filter_annotations(labels, threshold=0.001, match='all')[source]
Return a Studyset filtered by annotation labels.
- filter_study_ids(study_ids)[source]
Return a Studyset keeping only analyses belonging to the given study IDs.
- classmethod from_dataset(dataset, *, materialize=True)[source]
Create a Studyset from a NiMARE Dataset.
- classmethod from_table_cache(table_cache, *, studyset_id='nimads_cached_tables', studyset_name='', target=None, mask=None, basepath=None, materializer=None, normalize_metadata=True)[source]
Create a lightweight Studyset backed by precomputed Dataset-style tables.
- get_analyses_by_annotations(key, value=None)[source]
Extract a list of Analyses with a given label/annotation.
- get_analyses_by_coordinate(xyz, r=None, n=None)[source]
Extract a list of Analyses with at least one Point near the requested coordinates.
- Parameters:
- Returns:
A list of Analysis IDs with at least one point within the search criteria.
- Return type:
Notes
Either r or n must be provided, but not both.
- get_analyses_by_label(labels=None, label_threshold=0.001)[source]
Extract analysis IDs whose annotation values exceed the threshold.
- get_analyses_by_mask(img)[source]
Extract a list of Analyses with at least one Point in the specified mask.
- get_analyses_by_metadata(key, value=None)[source]
Extract a list of Analyses with a metadata field/value.
- get_images(analyses=None, imtype=None, ids=None)[source]
Get image paths or collect nested Image objects by short analysis IDs.
- get_metadata(analyses=None, field=None, ids=None)[source]
Get metadata values or collect nested metadata by short analysis IDs.
- Parameters:
- Returns:
Nested metadata mapping or tabular metadata values, depending on the arguments.
- Return type:
- get_studies_by_coordinate(xyz, r=20)[source]
Extract full analysis IDs with at least one focus near the requested coordinates.
- get_studies_by_label(labels=None, label_threshold=0.001)[source]
Extract full analysis IDs whose annotation values exceed the threshold.
- get_texts(analyses=None, text_type=None, ids=None)[source]
Get texts for selected analyses or collect nested texts by short analysis IDs.
- property ids
1D array of full analysis identifiers.
- Type:
- property images
Dataset-like images table.
- Type:
- property is_execution_ready
Whether the Studyset has an explicit execution configuration.
- Type:
- property masker
Masker used for Dataset-like Studyset views.
- merge(right)[source]
Merge a separate Studyset into the current one.
- Parameters:
right (Studyset) – The other Studyset to merge with this one.
- Returns:
A new Studyset containing merged studies from both input Studysets. For studies with the same ID, their analyses and metadata are combined, with data from self (left) taking precedence in case of conflicts.
- Return type:
- property metadata
Dataset-like metadata table.
- Type:
- save(filename)[source]
Write the Studyset to a pickled file.
- Parameters:
filename (str) – Path where the pickled file should be saved.
- set_annotations_df(annotations_df, overwrite=True)[source]
Update analysis-level annotations from a flattened DataFrame.
- Parameters:
annotations_df (
pandas.DataFrame) – DataFrame with one row per analysis. Must contain either anidcolumn with Dataset-style full IDs (<study_id>-<analysis_id>) or bothstudy_idandcontrast_idcolumns from which the full IDs can be derived.overwrite (
bool, optional) – If True, replace each analysis’ existing annotation dictionary with the values fromannotations_df. Analyses absent from the DataFrame will have their annotations cleared. If False, merge new values into existing annotation dictionaries while leaving untouched analyses unchanged. Default is True.
- slice(ids=None, *, analyses=None, filter_level='analysis')[source]
Create a new Studyset keeping only the requested IDs.
- Parameters:
ids (
strorlistofstr, optional) – Identifiers to keep. Can also be passed via the deprecatedanalyseskeyword for backwards compatibility.analyses (
strorlistofstr, optional) – Deprecated alias for ids. Will be removed in a future release.filter_level (
"analysis"or"study", optional) – When"analysis"(default), ids are treated as analysis-level identifiers (full<study_id>-<analysis_id>strings or short analysis IDs). When"study", ids are treated as study-level identifiers and every analysis belonging to those studies is kept.
- Returns:
A new Studyset containing only the matching analyses.
- Return type:
- property space
Execution-space label used for Dataset-like Studyset views.
- property studies
Return the nested Study graph, materializing it on demand if needed.
- property study_ids
1D array of unique study identifiers.
Extracted from the full
<study_id>-<analysis_id>identifiers without materializing the nested Study graph.- Type:
- property texts
Dataset-like texts table.
- Type:
Examples using nimare.nimads.Studyset



Create a legacy NiMARE Dataset object from a JSON file

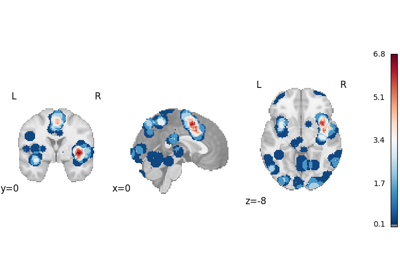
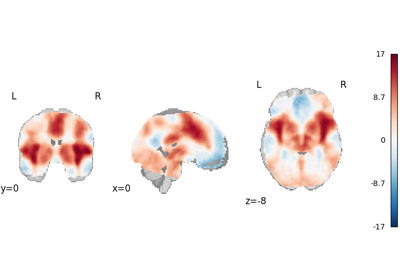
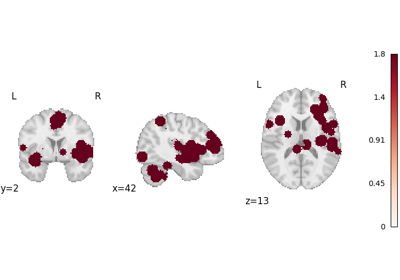
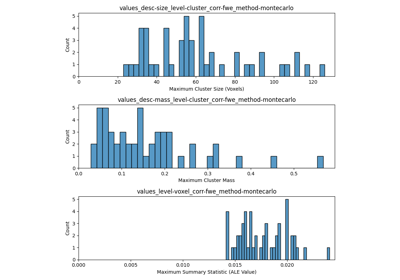

Run a coordinate-based meta-analysis (CBMA) workflow



Predictive ALE: fast FWE correction without Monte Carlo

Stability diagnostics: Jackknife vs. ResampledStability