Note
Go to the end to download the full example code.
Two-sample ALE meta-analysis
Meta-analytic projects often involve a number of common steps comparing two or more samples.
In this example, we replicate the ALE-based analyses from Enge et al.[1].
A common project workflow with two meta-analytic samples involves the following:
Run a within-sample meta-analysis of the first sample.
Characterize/summarize the results of the first meta-analysis.
Run a within-sample meta-analysis of the second sample.
Characterize/summarize the results of the second meta-analysis.
Compare the two samples with a subtraction analysis.
Compare the two within-sample meta-analyses with a conjunction analysis.
import os
from pathlib import Path
import matplotlib.pyplot as plt
from nilearn.plotting import plot_stat_map
Load Sleuth text files directly into Studysets
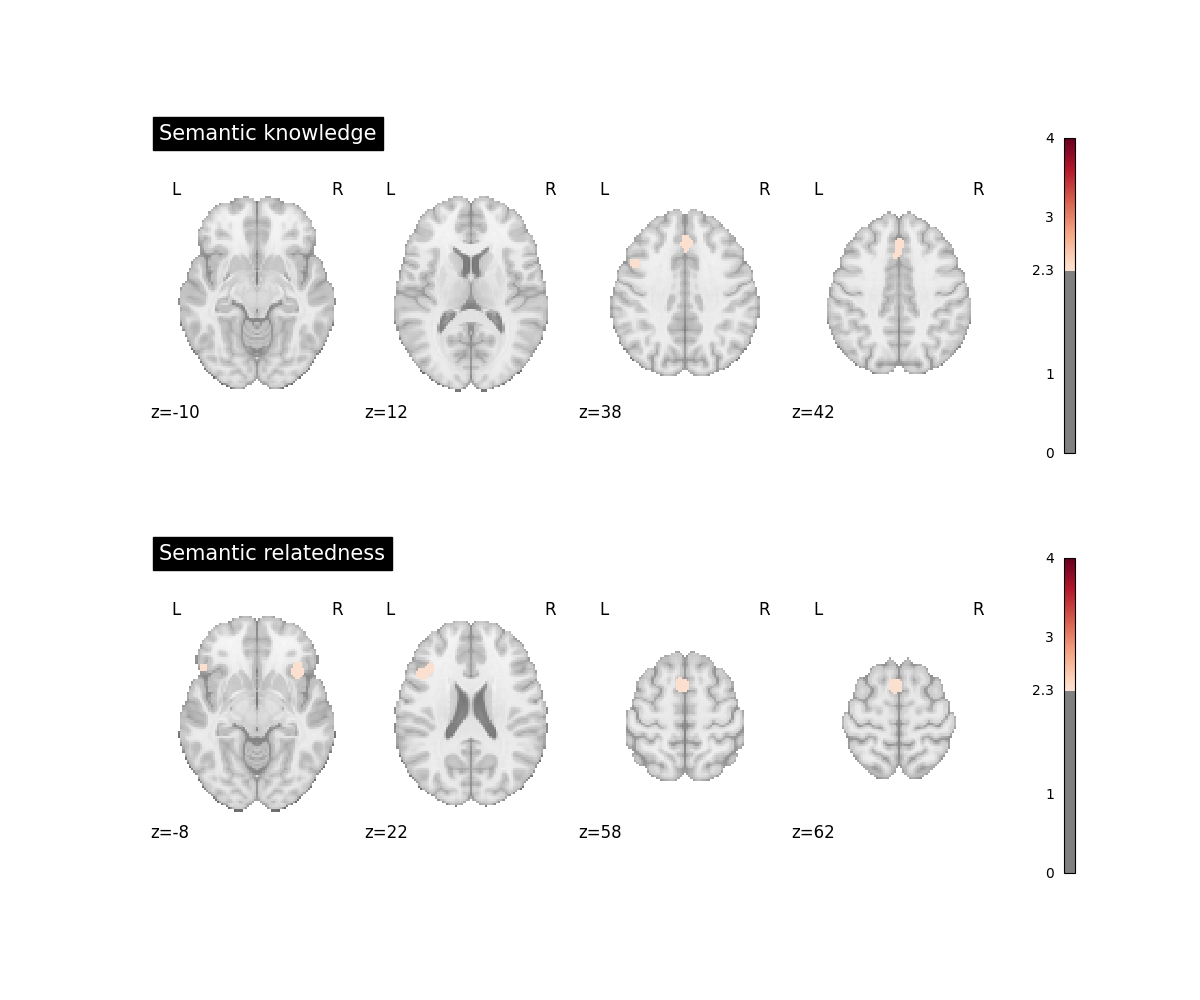
The data for this example are a subset of studies from a meta-analysis on semantic cognition in children [1]. A first group of studies probed children’s semantic world knowledge (e.g., correctly naming an object after hearing its auditory description) while a second group of studies asked children to decide if two (or more) words were semantically related to one another or not.
from nimare.io import convert_sleuth_to_studyset
from nimare.utils import get_resource_path
knowledge_file = os.path.join(get_resource_path(), "semantic_knowledge_children.txt")
related_file = os.path.join(get_resource_path(), "semantic_relatedness_children.txt")
knowledge_studyset = convert_sleuth_to_studyset(knowledge_file)
related_studyset = convert_sleuth_to_studyset(related_file)
Individual group ALEs
Computing separate ALE analyses for each group is not strictly necessary for performing the subtraction analysis but will help the experimenter to appreciate the similarities and differences between the groups.
from nimare.correct import FWECorrector
from nimare.meta.cbma import ALE
ale = ALE(null_method="approximate")
knowledge_results = ale.fit(knowledge_studyset)
related_results = ale.fit(related_studyset)
corr = FWECorrector(method="montecarlo", voxel_thresh=0.001, n_iters=100, n_cores=2)
knowledge_corrected_results = corr.transform(knowledge_results)
related_corrected_results = corr.transform(related_results)
fig, axes = plt.subplots(figsize=(12, 10), nrows=2)
knowledge_img = knowledge_corrected_results.get_map(
"z_desc-size_level-cluster_corr-FWE_method-montecarlo"
)
plot_stat_map(
knowledge_img,
cut_coords=4,
display_mode="z",
title="Semantic knowledge",
threshold=2.326, # cluster-level p < .01, one-tailed
cmap="RdBu_r",
symmetric_cbar=True,
vmax=4,
axes=axes[0],
figure=fig,
)
related_img = related_corrected_results.get_map(
"z_desc-size_level-cluster_corr-FWE_method-montecarlo"
)
plot_stat_map(
related_img,
cut_coords=4,
display_mode="z",
title="Semantic relatedness",
threshold=2.326, # cluster-level p < .01, one-tailed
cmap="RdBu_r",
symmetric_cbar=True,
vmax=4,
axes=axes[1],
figure=fig,
)
fig.show()
0%| | 0/100 [00:00<?, ?it/s]
1%| | 1/100 [00:00<00:12, 7.91it/s]
3%|▎ | 3/100 [00:00<00:06, 13.99it/s]
5%|▌ | 5/100 [00:00<00:05, 16.23it/s]
7%|▋ | 7/100 [00:00<00:05, 17.40it/s]
9%|▉ | 9/100 [00:00<00:05, 17.53it/s]
11%|█ | 11/100 [00:00<00:04, 17.99it/s]
13%|█▎ | 13/100 [00:00<00:04, 18.31it/s]
15%|█▌ | 15/100 [00:00<00:04, 18.81it/s]
17%|█▋ | 17/100 [00:00<00:04, 18.91it/s]
19%|█▉ | 19/100 [00:01<00:04, 18.45it/s]
21%|██ | 21/100 [00:01<00:04, 18.77it/s]
23%|██▎ | 23/100 [00:01<00:04, 18.92it/s]
25%|██▌ | 25/100 [00:01<00:03, 19.00it/s]
27%|██▋ | 27/100 [00:01<00:03, 18.84it/s]
29%|██▉ | 29/100 [00:01<00:03, 19.03it/s]
31%|███ | 31/100 [00:01<00:03, 19.12it/s]
33%|███▎ | 33/100 [00:01<00:03, 19.01it/s]
35%|███▌ | 35/100 [00:01<00:03, 19.11it/s]
37%|███▋ | 37/100 [00:02<00:03, 19.16it/s]
39%|███▉ | 39/100 [00:02<00:03, 19.26it/s]
41%|████ | 41/100 [00:02<00:03, 19.11it/s]
43%|████▎ | 43/100 [00:02<00:03, 18.47it/s]
45%|████▌ | 45/100 [00:02<00:02, 18.62it/s]
49%|████▉ | 49/100 [00:02<00:02, 18.65it/s]
51%|█████ | 51/100 [00:02<00:02, 18.71it/s]
53%|█████▎ | 53/100 [00:02<00:02, 18.79it/s]
56%|█████▌ | 56/100 [00:02<00:02, 21.40it/s]
59%|█████▉ | 59/100 [00:03<00:02, 18.45it/s]
61%|██████ | 61/100 [00:03<00:02, 18.45it/s]
63%|██████▎ | 63/100 [00:03<00:01, 18.57it/s]
65%|██████▌ | 65/100 [00:03<00:01, 18.69it/s]
67%|██████▋ | 67/100 [00:03<00:01, 18.81it/s]
69%|██████▉ | 69/100 [00:03<00:01, 18.85it/s]
71%|███████ | 71/100 [00:03<00:01, 18.87it/s]
75%|███████▌ | 75/100 [00:04<00:01, 19.14it/s]
77%|███████▋ | 77/100 [00:04<00:01, 19.17it/s]
79%|███████▉ | 79/100 [00:04<00:01, 19.19it/s]
81%|████████ | 81/100 [00:04<00:00, 19.01it/s]
83%|████████▎ | 83/100 [00:04<00:00, 19.08it/s]
85%|████████▌ | 85/100 [00:04<00:00, 19.12it/s]
87%|████████▋ | 87/100 [00:04<00:00, 19.10it/s]
89%|████████▉ | 89/100 [00:04<00:00, 19.18it/s]
91%|█████████ | 91/100 [00:04<00:00, 19.27it/s]
93%|█████████▎| 93/100 [00:04<00:00, 18.72it/s]
95%|█████████▌| 95/100 [00:05<00:00, 18.96it/s]
99%|█████████▉| 99/100 [00:05<00:00, 19.26it/s]
100%|██████████| 100/100 [00:05<00:00, 18.93it/s]
0%| | 0/100 [00:00<?, ?it/s]
2%|▏ | 2/100 [00:00<00:05, 17.46it/s]
5%|▌ | 5/100 [00:00<00:05, 17.87it/s]
8%|▊ | 8/100 [00:00<00:04, 22.01it/s]
11%|█ | 11/100 [00:00<00:04, 20.70it/s]
14%|█▍ | 14/100 [00:00<00:03, 22.40it/s]
17%|█▋ | 17/100 [00:00<00:04, 20.65it/s]
20%|██ | 20/100 [00:00<00:03, 22.59it/s]
23%|██▎ | 23/100 [00:01<00:03, 21.25it/s]
26%|██▌ | 26/100 [00:01<00:03, 23.30it/s]
29%|██▉ | 29/100 [00:01<00:03, 21.21it/s]
33%|███▎ | 33/100 [00:01<00:03, 21.72it/s]
37%|███▋ | 37/100 [00:01<00:02, 21.92it/s]
41%|████ | 41/100 [00:01<00:02, 21.88it/s]
45%|████▌ | 45/100 [00:02<00:02, 21.98it/s]
49%|████▉ | 49/100 [00:02<00:02, 21.91it/s]
53%|█████▎ | 53/100 [00:02<00:02, 21.84it/s]
57%|█████▋ | 57/100 [00:02<00:01, 22.18it/s]
61%|██████ | 61/100 [00:02<00:01, 22.19it/s]
64%|██████▍ | 64/100 [00:02<00:01, 23.41it/s]
67%|██████▋ | 67/100 [00:03<00:01, 21.63it/s]
71%|███████ | 71/100 [00:03<00:01, 22.00it/s]
75%|███████▌ | 75/100 [00:03<00:01, 22.02it/s]
79%|███████▉ | 79/100 [00:03<00:00, 22.12it/s]
83%|████████▎ | 83/100 [00:03<00:00, 21.93it/s]
87%|████████▋ | 87/100 [00:03<00:00, 22.16it/s]
91%|█████████ | 91/100 [00:04<00:00, 22.00it/s]
95%|█████████▌| 95/100 [00:04<00:00, 22.18it/s]
99%|█████████▉| 99/100 [00:04<00:00, 22.07it/s]
100%|██████████| 100/100 [00:04<00:00, 22.11it/s]
Characterize the relative contributions of experiments in the ALE results
NiMARE contains two methods for this: Jackknife
and FocusCounter.
We will show both below, but for the sake of speed we will only apply one to
each subgroup meta-analysis.
from nimare.diagnostics import FocusCounter
counter = FocusCounter(
target_image="z_desc-size_level-cluster_corr-FWE_method-montecarlo",
voxel_thresh=None,
)
knowledge_diagnostic_results = counter.transform(knowledge_corrected_results)
0%| | 0/21 [00:00<?, ?it/s]
19%|█▉ | 4/21 [00:00<00:00, 37.51it/s]
38%|███▊ | 8/21 [00:00<00:00, 37.78it/s]
57%|█████▋ | 12/21 [00:00<00:00, 37.68it/s]
76%|███████▌ | 16/21 [00:00<00:00, 37.86it/s]
95%|█████████▌| 20/21 [00:00<00:00, 37.50it/s]
100%|██████████| 21/21 [00:00<00:00, 37.61it/s]
Clusters table.
knowledge_clusters_table = knowledge_diagnostic_results.tables[
"z_desc-size_level-cluster_corr-FWE_method-montecarlo_tab-clust"
]
knowledge_clusters_table.head(10)
Contribution table. Here PostiveTail refers to clusters with positive statistics.
knowledge_count_table = knowledge_diagnostic_results.tables[
"z_desc-size_level-cluster_corr-FWE_method-montecarlo_diag-FocusCounter"
"_tab-counts_tail-positive"
]
knowledge_count_table.head(10)
from nimare.diagnostics import Jackknife
jackknife = Jackknife(
target_image="z_desc-size_level-cluster_corr-FWE_method-montecarlo",
voxel_thresh=None,
)
related_diagnostic_results = jackknife.transform(related_corrected_results)
related_jackknife_table = related_diagnostic_results.tables[
"z_desc-size_level-cluster_corr-FWE_method-montecarlo_diag-Jackknife_tab-counts_tail-positive"
]
related_jackknife_table.head(10)
0%| | 0/16 [00:00<?, ?it/s]
6%|▋ | 1/16 [00:00<00:03, 3.85it/s]
12%|█▎ | 2/16 [00:00<00:03, 3.86it/s]
19%|█▉ | 3/16 [00:00<00:03, 3.89it/s]
25%|██▌ | 4/16 [00:01<00:03, 3.88it/s]
31%|███▏ | 5/16 [00:01<00:02, 3.86it/s]
38%|███▊ | 6/16 [00:01<00:02, 3.86it/s]
44%|████▍ | 7/16 [00:01<00:02, 3.86it/s]
50%|█████ | 8/16 [00:02<00:02, 3.86it/s]
56%|█████▋ | 9/16 [00:02<00:01, 3.85it/s]
62%|██████▎ | 10/16 [00:02<00:01, 3.86it/s]
69%|██████▉ | 11/16 [00:02<00:01, 3.82it/s]
75%|███████▌ | 12/16 [00:03<00:01, 3.83it/s]
81%|████████▏ | 13/16 [00:03<00:00, 3.85it/s]
88%|████████▊ | 14/16 [00:03<00:00, 3.87it/s]
94%|█████████▍| 15/16 [00:03<00:00, 3.89it/s]
100%|██████████| 16/16 [00:04<00:00, 3.89it/s]
100%|██████████| 16/16 [00:04<00:00, 3.86it/s]
Subtraction analysis
Typically, one would use at least 5000 iterations for a subtraction analysis. However, we have reduced this to 100 iterations for this example. Here we use a cluster-defining p-threshold of 0.01 for Monte Carlo FWE correction. In practice one would generally use a more stringent threshold.
from nimare.meta.cbma import ALESubtraction
from nimare.reports.base import run_reports
from nimare.workflows import PairwiseCBMAWorkflow
subtraction_iters = 100
subtraction_voxel_thresh = 0.01
# Keep estimator and Corrector Monte Carlo parameters synchronized so the
# correction step can reuse cached permutation nulls from ALESubtraction.
subtraction_estimator = ALESubtraction(
n_iters=subtraction_iters,
voxel_thresh=subtraction_voxel_thresh,
vfwe_only=False,
n_cores=1,
)
subtraction_corrector = FWECorrector(
method="montecarlo",
voxel_thresh=subtraction_voxel_thresh,
n_iters=subtraction_iters,
n_cores=1,
vfwe_only=False,
)
workflow = PairwiseCBMAWorkflow(
estimator=subtraction_estimator,
corrector=subtraction_corrector,
diagnostics=FocusCounter(voxel_thresh=0.01, display_second_group=True),
)
res_sub = workflow.fit(knowledge_studyset, related_studyset)
0%| | 0/100 [00:00<?, ?it/s]
6%|▌ | 6/100 [00:00<00:01, 57.85it/s]
13%|█▎ | 13/100 [00:00<00:01, 60.63it/s]
20%|██ | 20/100 [00:00<00:01, 61.62it/s]
27%|██▋ | 27/100 [00:00<00:01, 62.24it/s]
34%|███▍ | 34/100 [00:00<00:01, 62.68it/s]
41%|████ | 41/100 [00:00<00:00, 62.88it/s]
48%|████▊ | 48/100 [00:00<00:00, 62.93it/s]
55%|█████▌ | 55/100 [00:00<00:00, 62.06it/s]
62%|██████▏ | 62/100 [00:00<00:00, 62.09it/s]
69%|██████▉ | 69/100 [00:01<00:00, 62.11it/s]
76%|███████▌ | 76/100 [00:01<00:00, 62.21it/s]
83%|████████▎ | 83/100 [00:01<00:00, 62.11it/s]
90%|█████████ | 90/100 [00:01<00:00, 62.70it/s]
97%|█████████▋| 97/100 [00:01<00:00, 62.78it/s]
100%|██████████| 100/100 [00:01<00:00, 62.32it/s]
/home/docs/checkouts/readthedocs.org/user_builds/nimare/checkouts/latest/nimare/diagnostics.py:324: UserWarning: Attention: At least one of the (sub)peaks falls outside of the cluster body. Identifying the nearest in-cluster voxel.
clusters_table, label_maps = get_clusters_table(
0%| | 0/21 [00:00<?, ?it/s]
5%|▍ | 1/21 [00:00<00:19, 1.01it/s]
10%|▉ | 2/21 [00:01<00:18, 1.01it/s]
14%|█▍ | 3/21 [00:02<00:17, 1.01it/s]
19%|█▉ | 4/21 [00:04<00:17, 1.02s/it]
24%|██▍ | 5/21 [00:05<00:17, 1.07s/it]
29%|██▊ | 6/21 [00:06<00:16, 1.09s/it]
33%|███▎ | 7/21 [00:07<00:15, 1.08s/it]
38%|███▊ | 8/21 [00:08<00:13, 1.07s/it]
43%|████▎ | 9/21 [00:09<00:12, 1.05s/it]
48%|████▊ | 10/21 [00:10<00:11, 1.06s/it]
52%|█████▏ | 11/21 [00:11<00:10, 1.04s/it]
57%|█████▋ | 12/21 [00:12<00:09, 1.08s/it]
62%|██████▏ | 13/21 [00:13<00:08, 1.06s/it]
67%|██████▋ | 14/21 [00:14<00:07, 1.04s/it]
71%|███████▏ | 15/21 [00:15<00:06, 1.02s/it]
76%|███████▌ | 16/21 [00:16<00:05, 1.03s/it]
81%|████████ | 17/21 [00:17<00:04, 1.03s/it]
86%|████████▌ | 18/21 [00:18<00:03, 1.01s/it]
90%|█████████ | 19/21 [00:19<00:02, 1.02s/it]
95%|█████████▌| 20/21 [00:20<00:01, 1.01s/it]
100%|██████████| 21/21 [00:21<00:00, 1.03s/it]
100%|██████████| 21/21 [00:21<00:00, 1.04s/it]
0%| | 0/16 [00:00<?, ?it/s]
6%|▋ | 1/16 [00:01<00:17, 1.16s/it]
12%|█▎ | 2/16 [00:02<00:15, 1.14s/it]
19%|█▉ | 3/16 [00:03<00:14, 1.14s/it]
25%|██▌ | 4/16 [00:04<00:13, 1.12s/it]
31%|███▏ | 5/16 [00:05<00:12, 1.11s/it]
38%|███▊ | 6/16 [00:06<00:11, 1.13s/it]
44%|████▍ | 7/16 [00:07<00:10, 1.12s/it]
50%|█████ | 8/16 [00:09<00:09, 1.20s/it]
56%|█████▋ | 9/16 [00:10<00:08, 1.18s/it]
62%|██████▎ | 10/16 [00:11<00:07, 1.19s/it]
69%|██████▉ | 11/16 [00:12<00:06, 1.22s/it]
75%|███████▌ | 12/16 [00:14<00:04, 1.21s/it]
81%|████████▏ | 13/16 [00:15<00:03, 1.21s/it]
88%|████████▊ | 14/16 [00:16<00:02, 1.23s/it]
94%|█████████▍| 15/16 [00:17<00:01, 1.22s/it]
100%|██████████| 16/16 [00:18<00:00, 1.22s/it]
100%|██████████| 16/16 [00:18<00:00, 1.19s/it]
Report
Finally, a NiMARE report is generated from the MetaResult. root_dir = Path(os.getcwd()).parents[1] / “docs” / “_build” Use the previous root to run the documentation locally.
root_dir = Path(os.getcwd()).parents[1] / "_readthedocs"
html_dir = root_dir / "html" / "auto_examples" / "02_meta-analyses" / "08_subtraction"
html_dir.mkdir(parents=True, exist_ok=True)
run_reports(res_sub, html_dir)
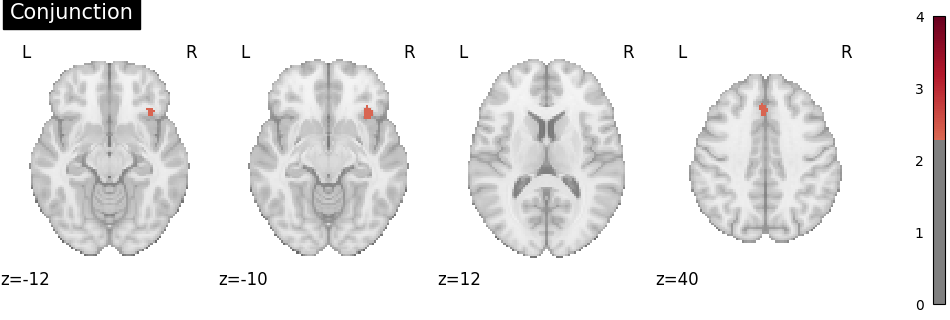
Conjunction analysis
To determine the overlap of the meta-analytic results, a conjunction image can be computed by (a) identifying voxels that were statistically significant in both individual group maps and (b) selecting, for each of these voxels, the smaller of the two group-specific z values Nichols et al.[2].
from nimare.workflows.misc import conjunction_analysis
img_conj = conjunction_analysis([knowledge_img, related_img])
plot_stat_map(
img_conj,
cut_coords=4,
display_mode="z",
title="Conjunction",
threshold=2.326, # cluster-level p < .01, one-tailed
cmap="RdBu_r",
symmetric_cbar=True,
vmax=4,
)
<nilearn.plotting.displays._slicers.ZSlicer object at 0x784a92402d50>
References
Total running time of the script: (1 minutes 46.515 seconds)